

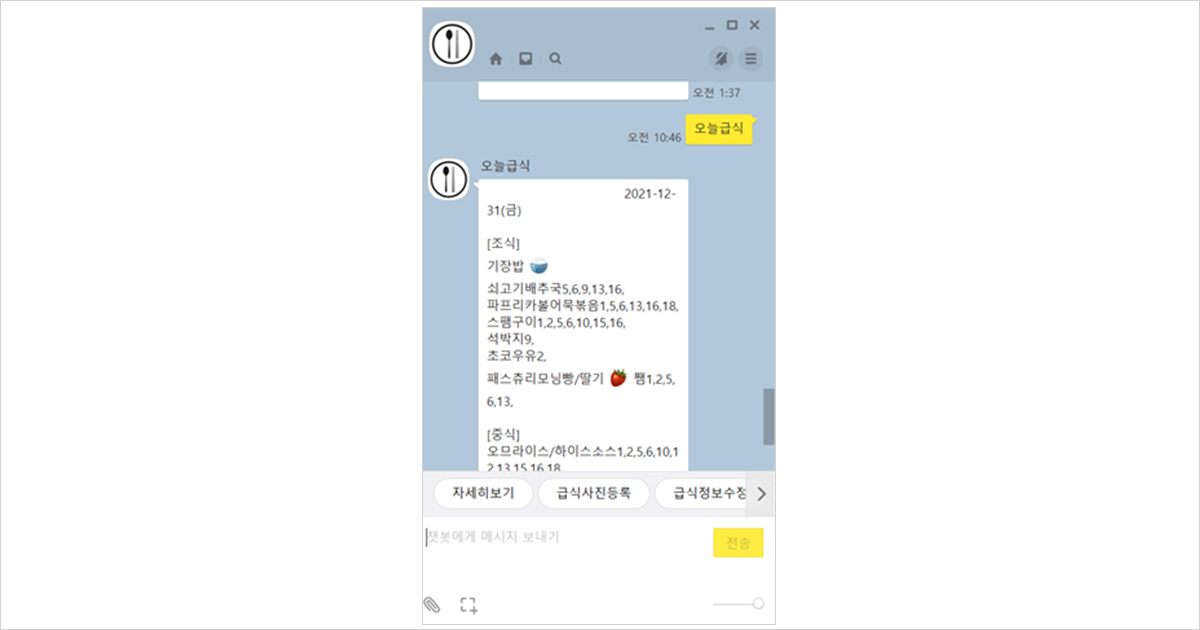
그림 1. 급식 챗봇 “오늘급식”
점심시간! 학교에서 가장 즐거운 시간 중 하나입니다. 힘든 아침 수업을 마치고, 점심식사로 보장받는 행복은 이루 말할 수 없죠. 여러분들은 급식에 무엇이 나올지 어떻게 아시나요? 단순히 가정통신문으로 급식 메뉴를 확인하거나 친구에게 물어볼 수도 있겠지만, 4차 산업혁명 시대를 살아가는 우리는 조금 더 스마트한 방법을 이용해 볼 수 있습니다. 바로 자동 챗봇을 이용하는 것입니다!
“오늘급식” 한 단어만 외치면, 눈 깜짝할 새에 오늘의 메뉴가 무엇인지 바로 불러올 수 있는 챗봇은 참 편리한 존재입니다. 저희 서울대학교에서도 비슷한 앱을 자주 사용하는데요, 바로 컴퓨터공학부 소속 동아리 “와플스튜디오”에서 제작한 “식샤”라는 앱입니다.
“오늘급식” 한 단어만 외치면, 눈 깜짝할 새에 오늘의 메뉴가 무엇인지 바로 불러올 수 있는 챗봇은 참 편리한 존재입니다. 저희 서울대학교에서도 비슷한 앱을 자주 사용하는데요, 바로 컴퓨터공학부 소속 동아리 “와플스튜디오”에서 제작한 “식샤”라는 앱입니다.
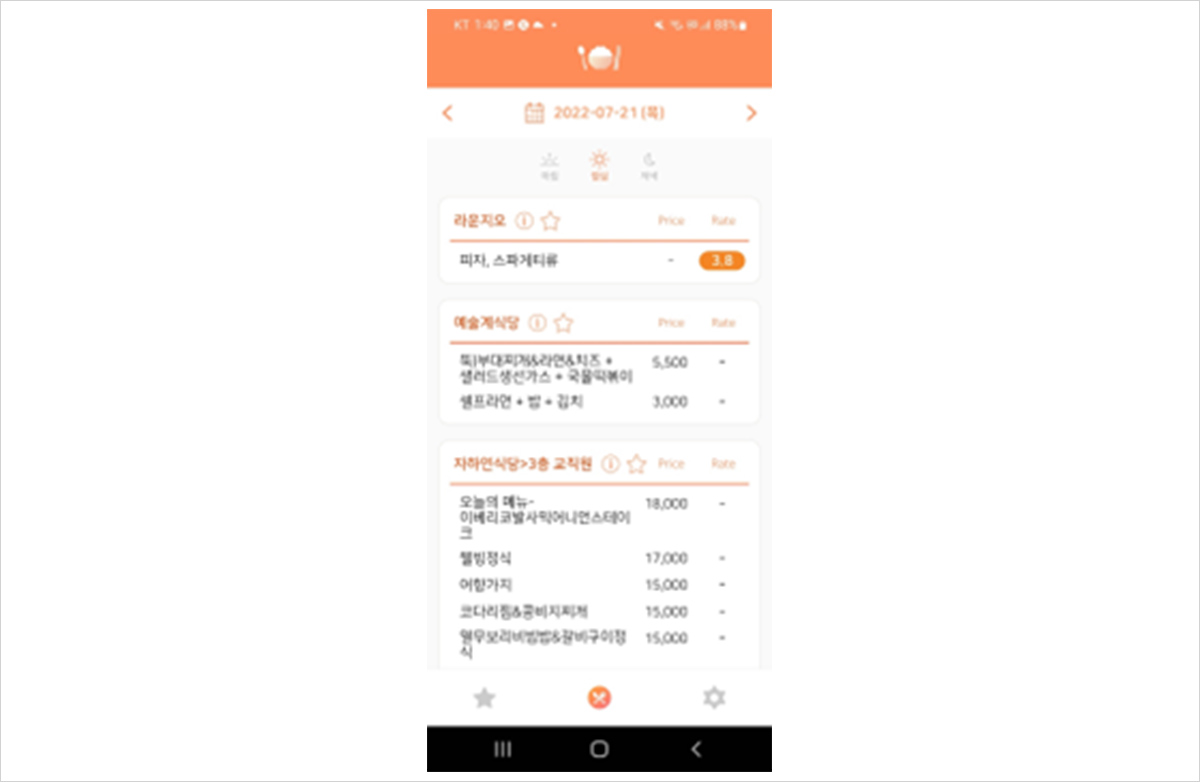
그림 2. 식샤 실행 화면
식샤 또한 마찬가지로 매일의 학식 메뉴를 알려주는 매우 편리한 앱입니다. 그런데, 이런 앱들은 어떻게 만들 수 있을까요? 날마다 변하는 급식 관련 정보를 계속해서 반영해야 하는데, 이를 인력이 아닌 코딩으로 해결할 수 있는 방법은 무엇일까요?
이를 해결하기 위해 급식 정보가 담겨 있는 웹사이트에서 데이터를 실시간으로 가져오는 방법을 생각해볼 수 있습니다. 이처럼 누군가가 인터넷상에 이미 올려놓은 정보를 프로그램을 활용해서 실시간으로 복사해오는 것을 크롤링(Crawling)이라고 합니다. 크롤링은 원래는 사람이 바닥을 기어가는 것을 의미하는데요, 인터넷으로 정보를 모으는 것을 마치 천천히 기어다니는 것에 비유하여 탄생한 단어입니다. 마찬가지로, 크롤링을 위해 사용하는 프로그램을 크롤러라고 부릅니다. 인터넷에는 항상 새로운 정보들이 빠른 속도로 업데이트되고 있습니다. 이런 새로운 정보들을 실시간으로 얻어오기 위해서는 크롤링이 제격입니다. 크롤링을 적절하게 활용하면, 날씨 정보를 실시간으로 얻어오거나, 인터넷에서 찾은 수많은 자료들을 내 마음대로 정리하는 등 사람이 직접 하기 어려운 일들을 아주 쉽게 해낼 수 있기 때문이죠.
이를 해결하기 위해 급식 정보가 담겨 있는 웹사이트에서 데이터를 실시간으로 가져오는 방법을 생각해볼 수 있습니다. 이처럼 누군가가 인터넷상에 이미 올려놓은 정보를 프로그램을 활용해서 실시간으로 복사해오는 것을 크롤링(Crawling)이라고 합니다. 크롤링은 원래는 사람이 바닥을 기어가는 것을 의미하는데요, 인터넷으로 정보를 모으는 것을 마치 천천히 기어다니는 것에 비유하여 탄생한 단어입니다. 마찬가지로, 크롤링을 위해 사용하는 프로그램을 크롤러라고 부릅니다. 인터넷에는 항상 새로운 정보들이 빠른 속도로 업데이트되고 있습니다. 이런 새로운 정보들을 실시간으로 얻어오기 위해서는 크롤링이 제격입니다. 크롤링을 적절하게 활용하면, 날씨 정보를 실시간으로 얻어오거나, 인터넷에서 찾은 수많은 자료들을 내 마음대로 정리하는 등 사람이 직접 하기 어려운 일들을 아주 쉽게 해낼 수 있기 때문이죠.
이번 기사에서는 NEIS(교육행정정보시스템) 웹사이트에서 제공되는 급식 정보를 크롤링해 볼 것입니다. 또, 매일 아침 정해진 시간마다 자동으로 데이터를 받아오게 함으로써 편리함을 극대화해보겠습니다. 코딩을 처음 해보신다고요? 괜찮습니다! 기본적인 기능 몇 가지만 숙지하면 내용을 쉽게 따라올 수 있으니, 포기하지 말고 읽어주세요! 만약 파이썬의 기초적인 문법을 조금 알고 있다면, 아래의 ‘응용’ 부분까지 구현하여 더욱더 좋은 결과물을 만들 수 있습니다. 전체 소스코드는 이곳(https://colorscripter.com/s/DrRNGVz) 에 있습니다. 소스코드를 보면서 기사를 읽으면 이해가 한결 쉬울 거예요.
코딩 전, 사전 준비하기
첫 번째로, 파이썬이라는 언어를 편하게 사용할 수 있게 하는 통합 개발 환경(Integrated Development Environment), IDE 프로그램을 설치할 것입니다. 1 대표적인 IDE로는 VSCode, Pycharm 등이 있습니다. 이번 기사에서는 초보자들이 사용하기 편한 파이참(Pycharm)을 기준으로 설명할게요. 구글에 “Pycharm”을 검색하면, JetBrains 사의 웹사이트를 찾을 수 있을 것입니다. “다운로드” 버튼을 누르고, 학생용인 Community 버전을 다운로드받은 후, exe 파일을 실행해 주면, 짜잔! 파이참이 설치됩니다!
그림 3과 같이 첫 창에서 새 프로젝트(New Project)를 선택해 새 프로젝트를 만들고, 좌측에 표시된 프로젝트 폴더를 우클릭해 [New] - [Python File]을 생성하면 여러분의 파이썬 파일을 만들 수 있습니다!
첫 번째로, 파이썬이라는 언어를 편하게 사용할 수 있게 하는 통합 개발 환경(Integrated Development Environment), IDE 프로그램을 설치할 것입니다. 1 대표적인 IDE로는 VSCode, Pycharm 등이 있습니다. 이번 기사에서는 초보자들이 사용하기 편한 파이참(Pycharm)을 기준으로 설명할게요. 구글에 “Pycharm”을 검색하면, JetBrains 사의 웹사이트를 찾을 수 있을 것입니다. “다운로드” 버튼을 누르고, 학생용인 Community 버전을 다운로드받은 후, exe 파일을 실행해 주면, 짜잔! 파이참이 설치됩니다!
그림 3과 같이 첫 창에서 새 프로젝트(New Project)를 선택해 새 프로젝트를 만들고, 좌측에 표시된 프로젝트 폴더를 우클릭해 [New] - [Python File]을 생성하면 여러분의 파이썬 파일을 만들 수 있습니다!
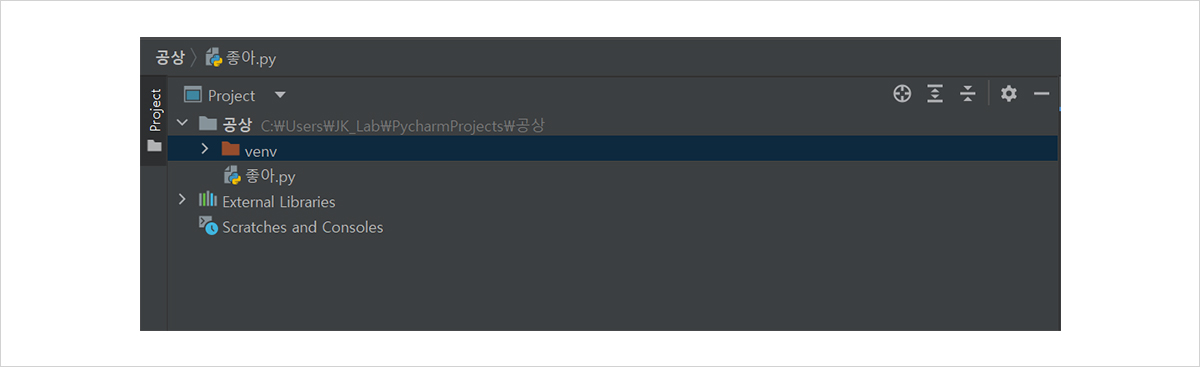
그림 3. 새 프로젝트를 만든 뒤 표시되는 창
파이썬 파일을 만들었다면, 이번 프로젝트에 필요한 라이브러리2 를 설치할 차례입니다. 저희는 인터넷에 접속해서 정보를 받아오기 위해 Requests라는 라이브러리를, 크롤링을 위해서는 Beautifulsoup라는 라이브러리를 활용할 건데요, 라이브러리가 무엇인지 아직 모르는 분들은 이전 호 기사(http://beengineers.snu-eng.kr/html/2203/s0203.html) 를 참고해 주세요! 그림 4와 같이 Pycharm 화면 아래에 있는 “Terminal” 탭을 클릭하고, 표시된 창에 “pip install bs4”를 입력해 beautifulsoup 라이브러리를 설치합니다.
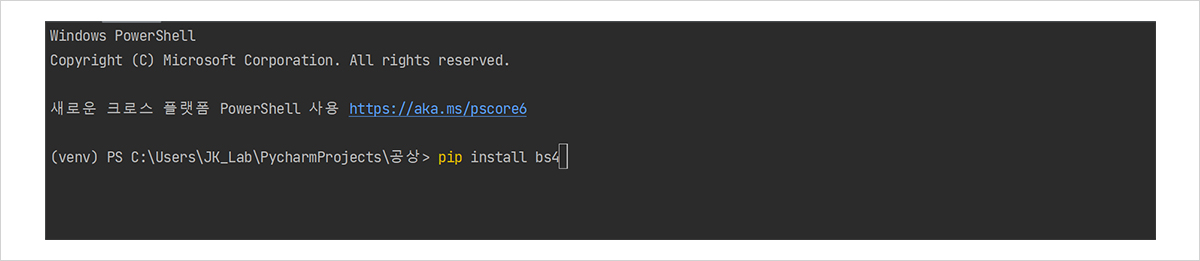
그림 4. 라이브러리 설치
이제 코딩을 위한 준비는 다 끝났습니다. 이제 저희가 사용할 데이터에 대해 알아보겠습니다. NEIS에서는 전국 초, 중, 고등학교의 급식 식단 정보를 저장 및 업데이트하고 있고, 이를 누구나 쉽게 사용할 수 있도록 API3 의 형태로 제공하고 있습니다. NEIS의 경우에는 주소창에 특정 옵션들을 입력함으로써 데이터를 얻어올 수 있게 하는 기능을 제공합니다.
이 링크(https://bit.ly/3J3Oq1Y)에 접속하면, 원하는 데이터를 얻기 위해 주소창에 입력할 수 있는 다양한 옵션들이 나열되어 있습니다. 예시(https://colorscripter.com/s/DrRNGVz)를 들어 설명해 보겠습니다.
그림 5의 예시 링크를 관찰해 봅시다.
그림 5의 예시 링크를 관찰해 봅시다.
1 통합 개발 환경(Integrated Development Environment)의 약자로, 단순히 어떤 언어로 프로그램을 작성하는 기능뿐만 아니라, 소프트웨어를 개발할 때 거의 필수적인 컴파일, 디버깅, 코드 하이라이팅 등의 유용한 기능을 사용할 수 있는 환경을 제공하는 프로그램입니다.
2 기본 파이썬에서는 제공되지 않는 다양한 함수들을 사용할 수 있게 하는 외부 파일을 뜻합니다. 파이썬의 기능을 확장함으로서 훨씬 유연한 코딩을 할 수 있게 한답니다.
3 다양한 데이터 혹은 기능을 우리가 쉽게 사용할 수 있도록 몇 가지 약속을 해 놓은 것을 말합니다. 예를 들어, 이번 프로젝트에서는 주소창에 약속된 형식대로 검색을 진행하면 데이터를 얻을 수 있습니다.
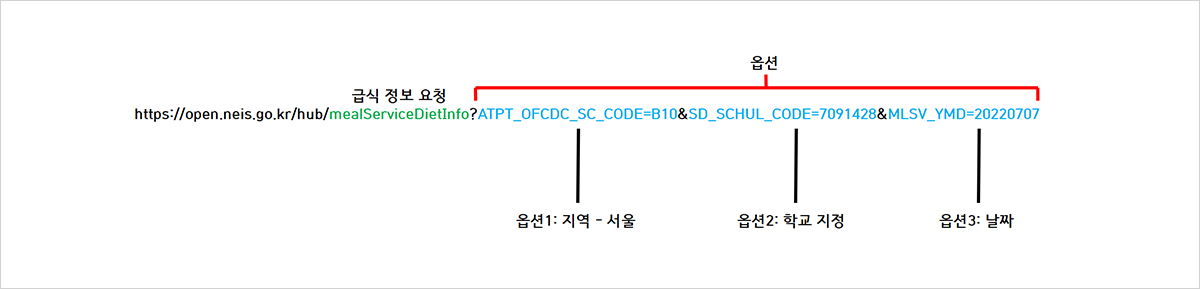
그림 5. 예시 링크
예시 링크에 접속하면, 한 학교의 7월 7일 급식 정보가 나타날 것입니다. 이는 링크에 학교와 날짜를 지정해주었기 때문입니다. 위 링크처럼 원하는 학교의 지역과 학교 코드를 검색해서, 항목 1과 항목 2 자리에 넣고, 날짜를 지정해서 동일한 형식의 링크를 만들어 접속하면 원하는 학교의 급식 정보를 자유자재로 얻어올 수 있습니다.

그림 6. 예시 링크 접속 시 나타나는 화면
이 링크에 접속하면 위와 같은 특이한 형태의 문서가 나타나는데요. 저희가 할 일은 저 수많은 데이터 속에서 급식에 관련된 정보만을 크롤링으로 가져오는 것입니다. 이제 직접 코딩을 시작해봅시다!
라이브러리 불러오기
파이썬에는 ‘메서드(method)’라는 개념이 있습니다. 메서드가 무엇인지 궁금한 분들은 이전 <어때요 코딩 참 쉽죠?> 기사를 참고해 주세요. 우리는 requests에서 제공하는 메서드를 이용해 웹사이트의 URL을 넣어 인터넷 연결을 받아올 것이고, BeautifulSoup에서 제공하는 메서드를 이용해 받아온 웹사이트를 우리가 아는 데이터 형태로 가공할 것입니다.
라이브러리 내부 함수를 모두 가져올 수 있는 import와 from 명령어로 우리에게 필요한 라이브러리를 불러와 사용할 수 있습니다.
파이썬에는 ‘메서드(method)’라는 개념이 있습니다. 메서드가 무엇인지 궁금한 분들은 이전 <어때요 코딩 참 쉽죠?> 기사를 참고해 주세요. 우리는 requests에서 제공하는 메서드를 이용해 웹사이트의 URL을 넣어 인터넷 연결을 받아올 것이고, BeautifulSoup에서 제공하는 메서드를 이용해 받아온 웹사이트를 우리가 아는 데이터 형태로 가공할 것입니다.
라이브러리 내부 함수를 모두 가져올 수 있는 import와 from 명령어로 우리에게 필요한 라이브러리를 불러와 사용할 수 있습니다.

그림 7. 라이브러리 불러오기
그림 7과 같이 Requests와 BeautifulSoup 라이브러리를 불러옵니다. 위 두 명령어는 프로그램의 맨 위에 써 있어야 합니다.
크롤링을 이용한 불러오기
먼저, 데이터의 링크를 넣습니다. 우리가 사용했던 예시 링크에 따옴표를 달아 Url이라는 변수에 저장해 줍니다. 그 후 url을 request.get, 즉 request 라이브러리의 get이라는 함수에 대입합니다. 그렇게 해서 나온 결과값, 즉 웹사이트의 내용을 response 변수에 저장합니다. 이를 코드로 표현하면 다음과 같습니다.
먼저, 데이터의 링크를 넣습니다. 우리가 사용했던 예시 링크에 따옴표를 달아 Url이라는 변수에 저장해 줍니다. 그 후 url을 request.get, 즉 request 라이브러리의 get이라는 함수에 대입합니다. 그렇게 해서 나온 결과값, 즉 웹사이트의 내용을 response 변수에 저장합니다. 이를 코드로 표현하면 다음과 같습니다.

그림 8. 사이트에 접속
이때 인터넷 연결이 불안정하다면 오류가 발생할 수 있으니 주의하세요! 이제 response에서 내부 텍스트 부분만 불러와 html_text라는 변수에 저장합니다. 그 뒤, html_text를 BeautifulSoup 함수에 대입해주면 함수는 내부의 내용을 적절히 가공해서 우리가 읽을 수 있는 형식으로 바꾸어 줍니다. 이를 print 함수를 이용해서 출력하면 됩니다. 여기까지의 내용을 코드로 쓰면 그림 9와 같습니다.

그림 9. 사이트의 내용 가져오기
여기에서, BeautifulSoup 함수에 들어간 두 번째 입력은 어떤 방식으로 읽어올지를 정하는 것입니다. ‘html.parser’을 대입하면 우리가 웹에서 주로 사용하는 형식으로 읽어오는 것이라고 생각하면 됩니다.
데이터 직접 출력
Ctrl+Shift+F10 단축키를 누르면 프로그램이 실행되며, 하단에 있는 결과 창에 결과물이 출력됩니다. (설정을 변경하였다면 하단이 아닌 다른 곳에 창이 있을 수도 있습니다.)
Ctrl+Shift+F10 단축키를 누르면 프로그램이 실행되며, 하단에 있는 결과 창에 결과물이 출력됩니다. (설정을 변경하였다면 하단이 아닌 다른 곳에 창이 있을 수도 있습니다.)

그림 10. 기초적인 데이터를 출력한 결과물
그림 10처럼 가공되지 않은 결과물이 출력되었다면 성공입니다. 이제 결과를 조금 손질해서 필요한 데이터만 간단하게 나타내봅시다.
데이터 파싱하기
C파싱(Parsing)은 주어진 문장에서 우리가 원하는 데이터를 뽑아내는 것을 말합니다. 즉, 우리가 지금 하고자 하는 일은 결과물을 파싱하여 급식 데이터만을 얻는 것입니다. 어떤 방법으로 파싱을 해볼 수 있을까요?
생각할 수 있는 가장 단순한 방법은 전체 결과물을 반복문을 통해 돌아보다가, 급식메뉴와 관련된 내용이 나타나면 멈추고 그 부분만 출력하는 것입니다. 예를 들면 '쫄면', '김밥'과 같은 메뉴 이름을 미리 저장해 두었다가 일치하는 문자가 나타나면 출력하는 것이지요. 그러나 우리가 모든 급식의 종류를 미리 써놓을 수 없기 때문에 이 방법을 사용하는 것에 한계가 있습니다. 그럼 더 정확한 방법을 사용해 볼까요?
우리가 출력한 데이터를 잘 관찰해 봅시다. 모든 줄이 꺾쇠(<)로 둘러싸인 이름표로 관리되고 있다는 것을 확인할 수 있습니다. 이러한 형식의 문서를 XML 문서라고 합니다. 저 이름표를 ‘태그’ 라고 부르며, 태그 내부에 있는 내용을 설명하는 역할을 합니다. BeautifulSoup은 XML 문서들에 대한 강력한 파싱 기능을 제공하며, 각 태그 내부의 내용을 쉽게 가져올 수 있는 메서드들을 제공합니다. 이제 직접 XML 문서를 읽어보며 각 태그의 역할을 더 깊게 파헤쳐 볼까요?
C파싱(Parsing)은 주어진 문장에서 우리가 원하는 데이터를 뽑아내는 것을 말합니다. 즉, 우리가 지금 하고자 하는 일은 결과물을 파싱하여 급식 데이터만을 얻는 것입니다. 어떤 방법으로 파싱을 해볼 수 있을까요?
생각할 수 있는 가장 단순한 방법은 전체 결과물을 반복문을 통해 돌아보다가, 급식메뉴와 관련된 내용이 나타나면 멈추고 그 부분만 출력하는 것입니다. 예를 들면 '쫄면', '김밥'과 같은 메뉴 이름을 미리 저장해 두었다가 일치하는 문자가 나타나면 출력하는 것이지요. 그러나 우리가 모든 급식의 종류를 미리 써놓을 수 없기 때문에 이 방법을 사용하는 것에 한계가 있습니다. 그럼 더 정확한 방법을 사용해 볼까요?
우리가 출력한 데이터를 잘 관찰해 봅시다. 모든 줄이 꺾쇠(<)로 둘러싸인 이름표로 관리되고 있다는 것을 확인할 수 있습니다. 이러한 형식의 문서를 XML 문서라고 합니다. 저 이름표를 ‘태그’ 라고 부르며, 태그 내부에 있는 내용을 설명하는 역할을 합니다. BeautifulSoup은 XML 문서들에 대한 강력한 파싱 기능을 제공하며, 각 태그 내부의 내용을 쉽게 가져올 수 있는 메서드들을 제공합니다. 이제 직접 XML 문서를 읽어보며 각 태그의 역할을 더 깊게 파헤쳐 볼까요?

그림 11. 데이터 관찰, 태그들을 확인할 수 있다.
<mmeal_sc_nm> 이라는 태그부터 살펴보겠습니다. 우선 CDATA는 “Character DATA”의 약자로서, XML 문서 형식으로 파싱하지 않아도 되는 평문이라는 의미입니다. 우리가 원하는 데이터는 저 안에 있을 가능성이 높습니다. 실제로 “중식”이라는 데이터가 포함되어 있군요!
따라서 mmeal_sc_nm이라는 태그 내부에는 아침, 점심, 저녁 중 어느 때인지가 나타나 있다는 것을 알 수 있습니다. 마찬가지로 몇몇 태그를 읽어 보겠습니다.는 20220707, 처음 입력한 날짜가 나와 있는 것으로 보아 이 급식이 나온 날짜를 의미합니다. <mlsv_fgr>의 “805”는 무슨 데이터일까요? 바로 급식 인원수를 의미합니다. <ddish_nm>이라는 태그 내부에는 메뉴에 대한 정보가 자세하게 포함되어 있군요! 이제 우리가 원하는 급식 메뉴 관련 정보가 담긴 태그는 ddish_nm이라는 것을 알 수 있습니다. 이렇게 데이터를 얻어오는 과정에서 각각이 무엇을 의미하는지 추측해보는 것도 크롤링의 재미랍니다.
BeautifulSoup의 find_all 함수를 활용하여, 아까 우리가 출력한 결과물 soup에서 특정 태그 내부의 내용만을 파싱할 수 있습니다. 이를 dish_list에 저장하겠습니다. 이제 리스트 중 첫 번째 급식의 내용을 가져온다는 의미로 dish_list.get_text() 함수를 이용해 메뉴를 완전히 가져와서 출력해 보겠습니다. 현재까지의 내용을 코딩하고, 결과물을 아까와 마찬가지로 확인하면,
따라서 mmeal_sc_nm이라는 태그 내부에는 아침, 점심, 저녁 중 어느 때인지가 나타나 있다는 것을 알 수 있습니다. 마찬가지로 몇몇 태그를 읽어 보겠습니다.
BeautifulSoup의 find_all 함수를 활용하여, 아까 우리가 출력한 결과물 soup에서 특정 태그 내부의 내용만을 파싱할 수 있습니다. 이를 dish_list에 저장하겠습니다. 이제 리스트 중 첫 번째 급식의 내용을 가져온다는 의미로 dish_list.get_text() 함수를 이용해 메뉴를 완전히 가져와서 출력해 보겠습니다. 현재까지의 내용을 코딩하고, 결과물을 아까와 마찬가지로 확인하면,

그림 12. 태그 내용 가져오기

그림 13. 오늘의 급식
그림 13과 같이 우리가 원하는 내용이 잘 출력된 것을 확인할 수 있습니다. 우리는 7월 7일의 급식 데이터를 효과적으로 가져왔습니다! 만약 급식이 존재하지 않는 날의 데이터를 가져온다면 오류가 발생할 수 있으니 주의하세요. 출력물을 조금 더 깔끔하게 정리하는 방법은 그림 15와 같습니다.

그림 14. <br/>을 기준으로 문자열을 나눈 코드

그림 15. 다듬어진 결과물
관심이 생기신 독자분들은 파이썬의 ‘문자열 슬라이싱’, ‘문자열 관련 함수’에 관련하여 검색해 보시면 위 코드를 이해하실 수 있을 것입니다. 지금까지의 코드는 이 링크(http://colorscripter.com/s/VA9dW9K)에 있습니다. 위에서 설명한 것과 같이, 맨 위쪽 url 변수에서 날짜에 해당하는 옵션을 바꾸고, 학교코드와 지역코드를 바꿔주면 원하는 학교의 원하는 날짜에 대한 급식 데이터를 자유자재로 얻어올 수 있습니다.
응용: 매일매일 정보를 자동으로 얻어와보자!
지금까지 짠 프로그램만으로도 급식 정보는 충분히 알 수 있지만, 조금만 더 노력하면 정보를 매일매일 자동으로 받아오도록, 사용하기 더 편리한 프로그램을 만들 수 있습니다. 파이썬에는 시간을 관리하는 datetime, time이라는 라이브러리가 존재하는데요, 이들을 통해 일정한 시간이 되면 크롤링을 진행하고, 그 날의 급식 정보를 출력하도록 할 수 있습니다. 매초마다 시간을 확인하고, 시간이 아침 9시가 넘으면 크롤링을 하도록 코드를 짜 보겠습니다.
무한히 반복되는 코드는 while문을 사용해서 코딩하면 간편합니다. while문은 조건문이 참인 동안 동작하므로, while True: 반복문 내부에 있는 명령은 무한히 반복됩니다. 이제 time.sleep(1) 함수를 이용해 1초 간격으로 동작하게 하여, datetime.datetime.today()를 이용해 현재 시간을 불러와 9시가 넘었는지를 확인합니다.
지금까지 짠 프로그램만으로도 급식 정보는 충분히 알 수 있지만, 조금만 더 노력하면 정보를 매일매일 자동으로 받아오도록, 사용하기 더 편리한 프로그램을 만들 수 있습니다. 파이썬에는 시간을 관리하는 datetime, time이라는 라이브러리가 존재하는데요, 이들을 통해 일정한 시간이 되면 크롤링을 진행하고, 그 날의 급식 정보를 출력하도록 할 수 있습니다. 매초마다 시간을 확인하고, 시간이 아침 9시가 넘으면 크롤링을 하도록 코드를 짜 보겠습니다.
무한히 반복되는 코드는 while문을 사용해서 코딩하면 간편합니다. while문은 조건문이 참인 동안 동작하므로, while True: 반복문 내부에 있는 명령은 무한히 반복됩니다. 이제 time.sleep(1) 함수를 이용해 1초 간격으로 동작하게 하여, datetime.datetime.today()를 이용해 현재 시간을 불러와 9시가 넘었는지를 확인합니다.

그림 16. 시간을 얻어오는 코드
9시가 넘었으면 크롤링을 1번 진행해주면 됩니다. 0시가 되면 초기화해줍시다. 저는 이것을 chk라는 새로운 변수를 도입하여 구현하였습니다. 위의 시간을 얻어오는 코드를 조금 변형해 줍시다.
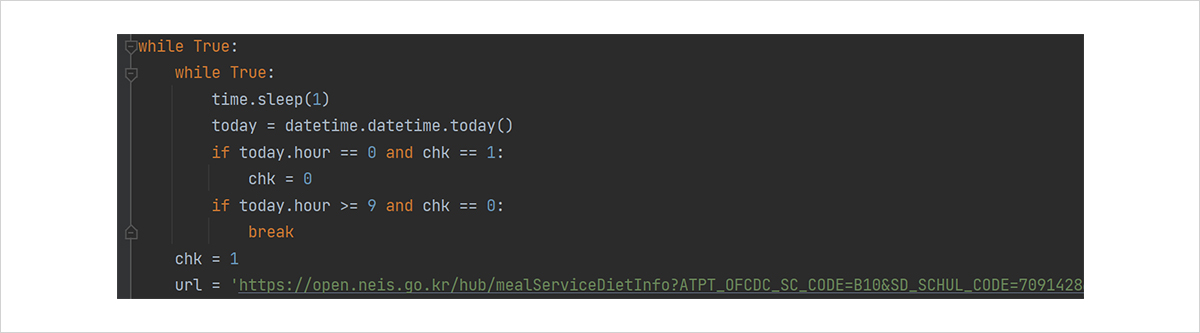
그림 17. 특정 시간마다 크롤링을 하는 코드
여기에서 if 명령어는, 제시하는 조건문이 참이라면 들여쓰기 안에 있는 명령어들을 실행하는 역할을 합니다. Break는 반복을 멈추는 역할이므로, 1초 간격으로 동작하던 것을 그만두라는 뜻이 됩니다.
그림 17의 코드를 해석해봅시다. 프로그램을 처음 실행하면 chk에 저장된 값은 0입니다. 만약 chk가 0인 상태에서 시간이 9시를 넘었다면 급식 메뉴를 출력하고 chk를 1로 바꿉니다. 이제는 시간이 9시가 넘어도, chk가 1이기 때문에 크롤링을 진행하지 않게 됩니다. 코드는 이곳(https://colorscripter.com/s/DrRNGVz)에 있습니다.
만약 여기까지 잘 따라오셨다면, 축하드립니다! 당신은 챗봇을 만들기 직전, 크롤러를 완성한 단계까지 도달했습니다. 이제 지금까지의 코드에 fbchat과 같은 간단한 메신저용 라이브러리를 가미해서 친구에게 급식 정보를 보내줄 수만 있다면 챗봇이 바로 완성됩니다. 그러나 코딩을 처음 하는 친구들에게는 꽤 어려운 내용일 수 있으므로 여기까지만 소개하도록 하겠습니다. 관심있는 친구들은 fbchat 라이브러리, Facebook/카카오톡 API4 등에 대해서 찾아보세요. 친구들이 깜짝 놀랄 결과물을 만들 수 있답니다.
그림 17의 코드를 해석해봅시다. 프로그램을 처음 실행하면 chk에 저장된 값은 0입니다. 만약 chk가 0인 상태에서 시간이 9시를 넘었다면 급식 메뉴를 출력하고 chk를 1로 바꿉니다. 이제는 시간이 9시가 넘어도, chk가 1이기 때문에 크롤링을 진행하지 않게 됩니다. 코드는 이곳(https://colorscripter.com/s/DrRNGVz)에 있습니다.
만약 여기까지 잘 따라오셨다면, 축하드립니다! 당신은 챗봇을 만들기 직전, 크롤러를 완성한 단계까지 도달했습니다. 이제 지금까지의 코드에 fbchat과 같은 간단한 메신저용 라이브러리를 가미해서 친구에게 급식 정보를 보내줄 수만 있다면 챗봇이 바로 완성됩니다. 그러나 코딩을 처음 하는 친구들에게는 꽤 어려운 내용일 수 있으므로 여기까지만 소개하도록 하겠습니다. 관심있는 친구들은 fbchat 라이브러리, Facebook/카카오톡 API4 등에 대해서 찾아보세요. 친구들이 깜짝 놀랄 결과물을 만들 수 있답니다.
4 이러한 데이터를 가져올 때에는 JSON이라는 형식을 사용하니 공부해 보시기를 추천합니다!
오늘은 간단한 크롤러를 직접 만들어 보고, 급식 챗봇들이 하는 것처럼 일정한 시간마다 급식 데이터들을 받아와 보았습니다. 이번 기사에서는 급식에 대해서만 다루었지만, 사실 수많은 데이터들을 크롤링을 이용해 받아올 수 있습니다. 날씨 정보, 특정 물건의 가격, 호텔의 예약 상태 등이 그 예시이지요. 이처럼 크롤링은 실시간으로 데이터들을 확인하고 나에게 알려줄 수 있는 좋은 조력자입니다. 기사에 등장한 내용들을 직접 찾아보면서, 나만의 크롤러를 만들어 보는 것은 예비 프로그래머로서 아주 좋은 경험이 될 것입니다. 이번 기사를 통해 크롤링의 매력을 깨달을 수 있는 기회가 되었길 바랍니다!
[전체 소스 코드]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import requests from bs4 import BeautifulSoup import datetime import time chk = 0 while True: while True: time.sleep(1) today = datetime.datetime.today() if today.hour == 0 and chk == 1: chk = 0 if today.hour >= 9 and chk == 0: break chk = 1 url = 'https://open.neis.go.kr/hub/mealServiceDietInfo?ATPT_OFCDC_SC_CODE=B10&SD_SCHUL_CODE=7091428&MLSV_YMD=' url = url + str(today.year) + str(today.month).zfill(2) + str(today.day).zfill(2) print(url) response = requests.get(url) html_text = response.text soup = BeautifulSoup(html_text, 'html.parser') dish_list = soup.find_all('ddish_nm') if len(dish_list)==0: print("No dish") else: menu = dish_list[0].get_text().split('<br/>') for i in menu: print(i) | cs |